
Komprise: »Kennen Sie Ihre Daten«
Die Verwaltung von aktiven und sogenannten kalten Daten überfordert viele Firmen. Welches sind aus Ihrer Sicht die Stolpersteine und welche Herangehensweise empfehlen Sie?
 Oksana Braune, KompriseBraune: Bisher war ein intelligentes Datenmanagement komplex und teuer: Daten waren in Silos gefangen, der Anwender hatte keine Einsicht in die Datenhaltung, -nutzung und -alterung. Zusätzlich hat es an der Automatisierung ohne Unterbrechung der User-Experience gehapert. Wir lösen diese Herausforderungen mit einem intelligenten Analytics-Driven Datenmanagement, das herstellerunabhängig ist und den Anwender in die Lage versetzt, die Kosten fürs Datenwachstum kontrollieren zu können. Die Daten werden erst analysiert und auf dieser Grundlage die Entscheidungen getroffen, wie und wohin man die nicht aktiven Daten verlagert. Die Ziele der günstigeren Speicherschicht sind hier frei wählbar zwischen On-Premises in der Private-Cloud oder Off-Premises in der Public-Cloud.
Oksana Braune, KompriseBraune: Bisher war ein intelligentes Datenmanagement komplex und teuer: Daten waren in Silos gefangen, der Anwender hatte keine Einsicht in die Datenhaltung, -nutzung und -alterung. Zusätzlich hat es an der Automatisierung ohne Unterbrechung der User-Experience gehapert. Wir lösen diese Herausforderungen mit einem intelligenten Analytics-Driven Datenmanagement, das herstellerunabhängig ist und den Anwender in die Lage versetzt, die Kosten fürs Datenwachstum kontrollieren zu können. Die Daten werden erst analysiert und auf dieser Grundlage die Entscheidungen getroffen, wie und wohin man die nicht aktiven Daten verlagert. Die Ziele der günstigeren Speicherschicht sind hier frei wählbar zwischen On-Premises in der Private-Cloud oder Off-Premises in der Public-Cloud.
Der Schlüssel für die neue, zeitgemäße Herangehensweise ist die Analyse und Sichtbarkeit der gespeicherten Daten und dann die Entscheidungsfindung über die Gestaltung der Datenspeicherstrategie.
Komprise verspricht ein intelligentes Datenmanagement und eine Senkung der Kosten für Sekundärspeicher. Wie darf man sich das in der Praxis vorstellen?
Braune: Hierzu werden unsere Administrations-Schnittstelle Komprise Director und mindestens zwei Observer als virtuelle Maschinen in der Umgebung des Kunden installiert. Die Observer verbinden sich mit NAS-Speicher als Clients und analysieren ausschließlich die Metadaten. Der Vorgang belastet nicht den Datenverkehr und ist Out-of-Band. Die Ergebnisse der Analyse werden an den Komprise Director gesendet. Dort definiert der Anwender seine Regelwerke in Bezug auf die günstigere Speicherschicht. Das heißt, welche Daten soll das System verschieben und welche Zugriffs- und weitere Berechtigungen sollen gesetzt werden.
Die Dateien am Ziel bleiben im nativen Format. Zudem setzen wir keine Agenten oder Stubs ein, sodass der Nutzer und seine Anwendungen wie gewohnt arbeiten können. Komprise Director ermittelt Kosteneinsparungen durch eine aussagekräftige ROI-Berechnung, die insbesondere für die kaufmännischen Entscheider im Unternehmen wichtig ist.
Der webbasierende Komprise Director lässt sich sowohl in der Cloud als auch in der Kundenumgebung betreiben. Observer sind die Software Komponenten, die an der Quelle (NAS oder Windows-File-Server) als Clients Metadaten analysieren und die Files Out-of-Band verwalten. Die minimale Konfiguration enthält redundante Observer. Um eine möglichst hohe Verfügbarkeit sicherzustellen, empfehlen wir mehr als zwei Observer.
Als neue Funktion kam zuletzt Deep-Analytics hinzu. Was darf man darunter verstehen?
Braune: Hier geht es darum, wie man die richtigen Daten unter Millionen von Dateien herausfindet, die im Unternehmen gespeichert sind. Komprise Deep Analytics ermöglicht das Suchen der richtigen Daten oder Datensätze über alle Speichersilos herstellerneutral sowohl On-Premises als auch über mehrere Public-Clouds wie AWS, Azure oder GCP. Das funktioniert über verschiedene Speicherorte und Speicherklassen hinweg. Die gesuchten und gefundenen Datensätze können markiert und mit anderen Dateien zu einem virtuellen Data-Lake für künstliche Intelligenz (KI) oder Machine-Learning (ML) innerhalb von Minuten zusammengefasst werden.
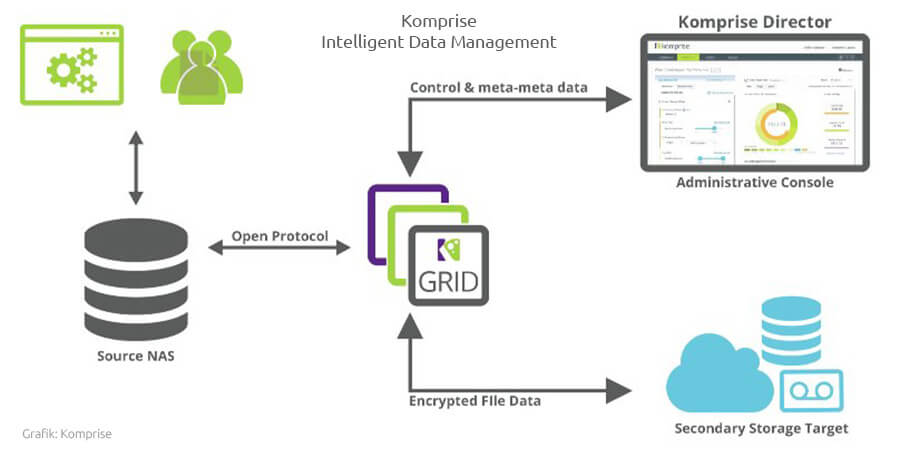 Aufbau von Komprise Intelligent Data Management
Aufbau von Komprise Intelligent Data Management
Wie sehen Sie die mittelfristige Entwicklung im Bereich Datenmanagement. Noch stehen wir ja am Anfang, eine gewisse Dynamik ist aber schon spürbar. Und wie steht Ihr zum Thema Archivierung? Könnte man mit einem revisionssicheren Medium das Thema Archivierung gleich mit »erschlagen«?
Braune: Die Archivierung war traditionell die Hauptstütze von Organisationen, die sich um die Einhaltung von Vorschriften bemühen. Die traditionellen technologischen Lösungen, die in diesem Bereich zur Verfügung standen, waren technisch komplex und sehr kostspielig, was zu schwierigen Implementierungen und steigenden Kosten führte.
Während die traditionelle Archivierung vielen Kundenerwartungen nicht gerecht wurde, war das Kernprinzip solide. In den letzten Jahren hat sich die Archivierung über die Traditionen der Einhaltung von Vorschriften hinaus erweitert. Im Allgemeinen ist dies darauf zurückzuführen, dass die Datensätze immer größer, die Backups immer umfangreicher und die Speicheroptionen immer vielfältiger werden.
Wenn wir ein traditionelles Datenzentrum in den 00er Jahren betrachten, würden wir TByte-Speicherkapazitäten finden, wobei die vorherrschenden Speichermedien SAS-Festplatten mit 15k U/min oder SATA-HDDs mit 7.200 U/min sind. In dieser Ära waren die Leistungs- und Preisunterschiede zwischen diesen Speichermedien relativ gering, und die Kapazitätspunkte zwar eine Herausforderung, aber überschaubar, was viele Unternehmen dazu veranlasste, Daten auf einer zentralen Plattform zu speichern, um sie einfach und leicht zu verwalten. Wenn wir uns auf den heutigen Tag zubewegen, finden wir viele Organisationen, die mit Multi-PByte-Umgebungen arbeiten, während sie mit einer verwirrenden Anzahl von Speicheroptionen und Preispunkten konfrontiert sind, die von NVMe mit extrem niedriger Latenzzeit bis hin zu extrem kostengünstigen Objektspeichern reichen. Diese unterschiedlichen Speicheroptionen sind mit einem ebenso unterschiedlichen Preispunkt verbunden, der die Möglichkeit der Speicherung aller Daten auf einer einzigen Plattform überflüssig macht.
Obwohl die meisten Unternehmen die Notwendigkeit verstehen, diese neuen Speichertechnologien zu nutzen, sehen sie sich in den meisten Fällen mit der unbequemen Wahrheit konfrontiert, dass ihnen jegliche Art von sinnvollem Wissen oder Verständnis über die Art, das Alter oder die Nutzung der gespeicherten und gesicherten Daten fehlt. Daher ist die erste Stufe jeder modernen Archivierungsstrategie das Verstehen durch Analyse, denn ohne sachliche Informationen über Speicherorte und Nutzungsraten von Daten wäre jede Archivierungspolitik nichts weiter als eine Vermutung.
Mit einer faktischen Information über die Datensätze können Entscheidungen über das richtige Speichermedium für jeden Datentyp getroffen werden. Der nächste Schritt oder die Archivierung sollte immer den Benutzer und die Anwendung berücksichtigen. Die Benutzer sind im Allgemeinen gegen einen Technologiewechsel, und daher sollte jede erfolgreiche Archivierungslösung für den Benutzer oder die Anwendung transparent sein. Der Schlüssel dazu ist die Schaffung eines plattformübergreifenden, einheitlichen Namensraums, der es den Benutzern ermöglicht, weiterhin auf alle Dateien in der heutigen Form zuzugreifen und gleichzeitig ihre Anfragen transparent auf die richtige Speicherplattform umzuleiten.
Schließlich müssen wir bedenken, dass sich die Daten und der Zugriff auf diese Daten ständig weiterentwickeln und die Archivierung daher kein einmaliger Prozess ist. Jede moderne Archivierungsplattform muss weiterhin den Datenzugriff überwachen und sicherstellen, dass die Daten während ihres gesamten Lebenszyklus immer auf dem relevantesten Speichermedium gespeichert sind.
- Komprise
- Produkt-Review: Komprise Intelligent Data Management verwaltet kalte Daten
- Videoanwenderbericht: Automatischer Workflow mit Datenmanagement beim Studio Hamburg