
Hammerspace Tier 0: Hochleistungsspeicher-Zukunft für KI & HPC
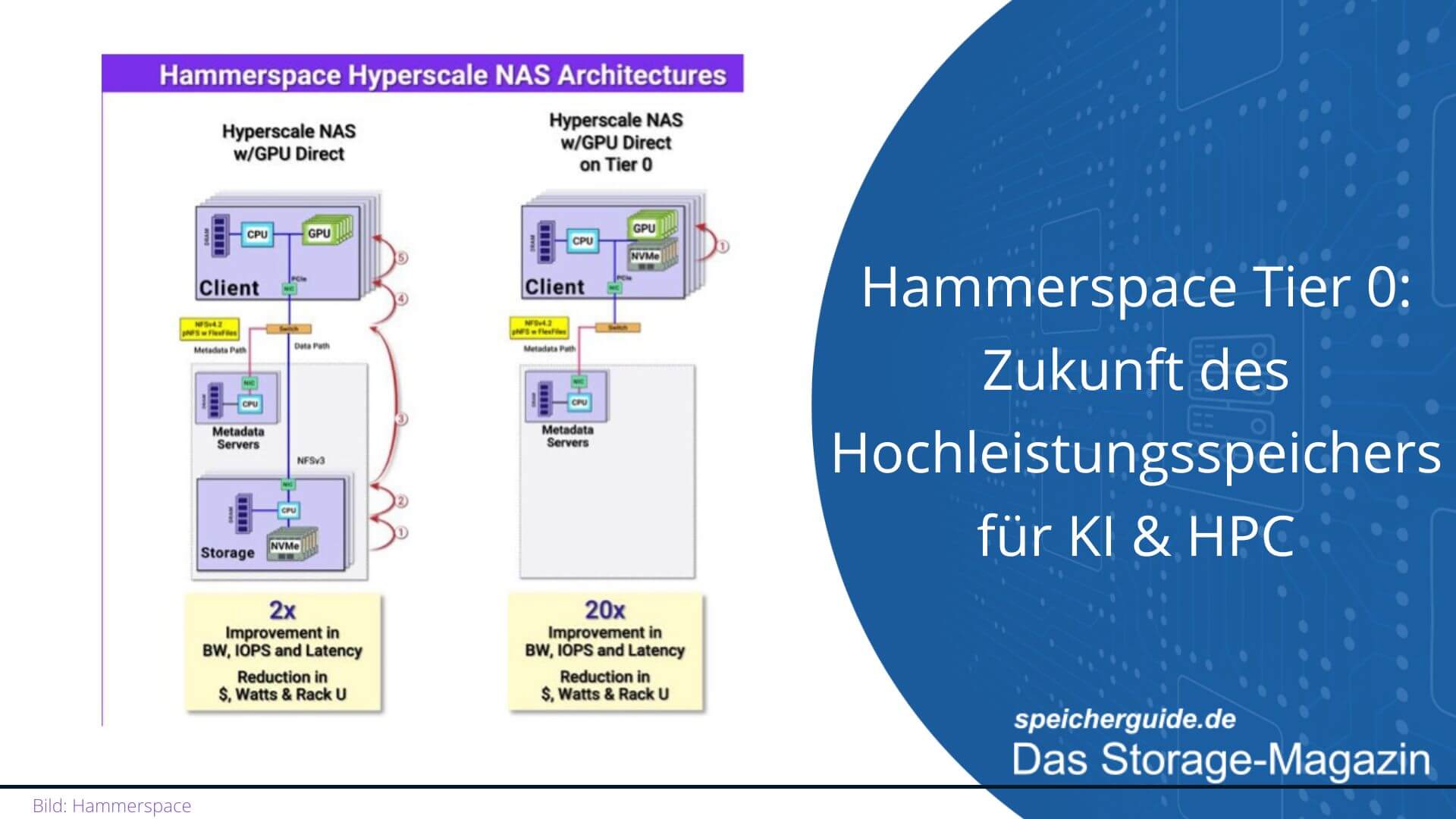 Hammerspace Tier 0 ist für leistungsstarke KI- und HPC-Anwendungen ausgelegt. Dabei werden unter anderem lokale NVMe-SSDs eines GPU-Servers zu einer gemeinsam nutzbare Speicher-Ressource, die eine beschleunigte Speicherzugriffszeit direkt am Ort der Datenverarbeitung ermöglichen. Dies soll Speicherengpässe beseitigen, Kosten senken, den Stromverbrauch reduzieren und GPU-Rechenzyklen freizusetzen.
Hammerspace Tier 0 ist für leistungsstarke KI- und HPC-Anwendungen ausgelegt. Dabei werden unter anderem lokale NVMe-SSDs eines GPU-Servers zu einer gemeinsam nutzbare Speicher-Ressource, die eine beschleunigte Speicherzugriffszeit direkt am Ort der Datenverarbeitung ermöglichen. Dies soll Speicherengpässe beseitigen, Kosten senken, den Stromverbrauch reduzieren und GPU-Rechenzyklen freizusetzen.
Für High-Performance-Computing (HPC) oder moderne Workloads wie das Training künstlicher Intelligenz (KI) ist die effiziente Nutzung von GPU-Ressourcen erfolgskritisch. Oft werden GPU-Cluster durch langsame Speicher- und Netzwerkinfrastrukturen ausgebremst. Lösungen wie die Global Data Platform von Hammerspace sollen Datensilos beseitigen und die Effizienz von Infrastruktur sowie GPUs steigern. Dazu integriert Hammerspace lokale NVMe-SSDs in GPU-Servern in sein Parallel Global File System. Das Ergebnis ist ein extrem schneller, gemeinsam nutzbarer Speicher für KI-, Enterprise HPC- und andere datenintensive Arbeitslasten. Jüngste Benchmark-Ergebnisse zeigen, dass dieses neue Tier 0 den Speicherzugriff spürbar beschleunigen und Kostenersparnisse ermöglichen kann.
GPU vs. Speicherinfrastruktur
GPUs sind teuer, schwer zu beschaffen und energiehungrig. Sie sollten daher nicht durch langsame Speicheroperationen ausgebremst werden. Herkömmliche Speicherarchitekturen können das nicht immer gewährleisten. Der Zugriff auf immense Datenmengen oder große Dateien aus externen Speichern überlasten selbst High-Speed-Netzwerke. Zur Leistungssteigerung werden klassische Scale-out-NAS-Landschaften dann gerne überdimensioniert, was Kosten und Energieverbrauch in die Höhe treibt. Eine Alternative sind die aus dem wissenschaftlichen HPC-Umfeld bekannten, jedoch in der Verwaltung komplexen parallelen Dateisysteme wie Lustre oder BeeGFS.
Durch die Kombination seiner Hyperscale NAS-Architektur, dem NFS Protocol Bypass (LOCALIO) und einer automatisierten Daten-Orchestrierung verwandelt Hammerspace Tier 0 den lokalen NVMe-Speicher von GPU-Servern in eine zusätzliche, hochperformante und gemeinsam nutzbare Speicher-Ressource.
Beim Einsatz großer GPU-Computing-Umgebungen (DGX, HGX usw.) ist die Zeit bis zur Wertschöpfung ebenso entscheidend wie Infrastrukturkosten und -beschränkungen. Bisher wird der lokale NVMe-Speicher auf GPU-Servern weitgehend nicht genutzt, weil er als zu isoliert betrachtet wird. GPU-Server verfügen – je nach Größe – über acht oder 16 SSDs und damit über bis zu 500 TByte Speicher (16 x 30,72 TByte = 491,52 TByte). Im Jahr 2025 erwartet man, dass bis zu 2 PByte Speicherplatz pro Server möglich sind. Notwendig sind die SSDs für das Betriebssystem (OS) der GPU-Server. Ein OS benötigt allerdings nur wenig Speicherplatz. Hammerspace ermöglicht mit seinem neuen Tier 0 die Nutzung dieser vernachlässigten Ressource; Daten für arbeitsintensive Workloads werden primär in diesem neuen Tier – dem lokalen NVMe-Speicher – abgelegt. Eine Linux-Kernel-Optimierung minimiert den Netzwerkpfad zwischen GPU und Tier 0, wodurch die Schreibgeschwindigkeit um das 10- bis 100-Fache verbessert wird, was die GPU-Nutzung optimiert. Da durch die Nutzung einer ohnehin verfügbaren Ressource weniger zusätzliche Hardware benötigt wird, können Unternehmen ihre Kosten reduzieren.
Eine neue Speicherklasse für KI<
Mit der auf Standards basierten, parallelen Dateisystem-Architektur und einem globalen Namespace verwaltet Hammerspace Speicher über verschiedene Systeme, Standorte und Clouds hinweg. Die Trennung des Metadatenverkehrs vom Datenpfad erleichtert es, Daten aus ihren Silos zu befreien. Hammerspace verwendet für sein High-Speed Data-Processing branchenübliche Protokolle und unterstützt unter anderem GPUDirect Storage sowie den direkten Datenpfad zwischen Linux-Clients und Storage-Backend. In Tier 0 setzt das innovative Unternehmen auf standardisierte Linux-Technologien wie LOCALIO: Befinden sich NFS-Client und -Server auf demselben Host, kann das Netzwerk-RPC-Protokoll für Lese-/Schreibvorgänge umgangen werden.
Mit seinem Ansatz will der Hersteller den Bedarf an Servern, Netzwerkkomponenten und Rack-Platz als auch Latenz sowie Stromverbrauch erheblich reduzieren.
Daten können entweder direkt in Tier 0 erstellt oder aus anderen Bereichen dorthin verschoben werden. Bestehende Dateien werden, egal wo sie sich befinden, sofort präsentiert – ohne dass sie kopiert oder verschoben werden müssen. Datenmigration ist ein optionaler Schritt, der unterbrechungsfrei im Hintergrund durchgeführt werden kann. David Flynn, Gründer und CEO von Hammerspace, betonte während der Vorstellung von Tier 0 im Rahmen der 60. IT Press Tour die Einfachheit: »Das ist wirklich bemerkenswert – das Ganze funktioniert, ohne dass irgendeine Hammerspace-Software auf diesen Knotenpunkten läuft.«
Das Einzige, was besser ist als ein schnelles Netzwerk, ist kein Netzwerk
Das Schreiben großer Datenmengen auf externe Netzwerkspeicher bringt erhebliche Herausforderungen mit sich. Neben GPU-Leerlaufzeiten und dem Risiko von Datenverlust überlasten gleichzeitige Schreibvorgänge die Netzwerk- und Speicherbandbreite zum Storage-Backend. Mit Tier 0 können Einschränkungen der Netzwerkbandbreite in klassischen Setups mit extern angebundenen Storagesystemen beseitigt werden. Durch die Verwendung von lokalem Speicher auf den Grafikprozessoren konnten sowohl Leistung als auch Auslastung der GPUs gesteigert werden. Zudem skalierte die Leistung linear, wenn dem Cluster weitere GPU-Server mit Tier-0-Speicher hinzugefügt wurden.
Bewiesen hat Hammerspace die Leistungsfähigkeit seines Tier 0 in einem MLPerf Storage Benchmark, der die Leistung von Speichersystemen für ML- und HPC-Workloads misst. Für den Benchmark wurde unter anderem eine On-Premises Tier 0-Umgebung mit lokalen NVMe-SSDs in GPU-Servern und dem NFS-Protokoll-Bypass LOCALIO untersucht.
Die Ergebnisse zeigen, dass Tier 0 es GPU-Servern ermöglichte, eine um 32 Prozent höhere GPU-Auslastung und einen um 28 Prozent höheren Gesamtdurchsatz zu erzielen. »Unsere MLPerf1.0-Benchmark-Ergebnisse sind ein Beweis für die Fähigkeit von Hammerspace Tier 0, das volle Potenzial der GPU-Infrastruktur auszuschöpfen«, bestätigt Hammerspace-CEO Flynn. „Durch die Beseitigung von Netzwerkbeschränkungen, die lineare Skalierung der Leistung und die Bereitstellung beispielloser finanzieller Vorteile setzt Tier 0 einen neuen Standard für KI- und HPC-Workloads.“
Ausfallsicherheit und Datenschutz inklusive
Ein weiterer wichtiger Baustein dafür ist die von Hammerspace verwendete Erasure-Coding-Technologie. Um eine leistungsstarke, effiziente und ausfallsichere Datenverwaltung zu gewährleisten, verwendet Hammerspace die Mojette-Transformation für ihr Erasure-Coding. Ursprünglich stammt die Methode aus dem Bereich der Bildverarbeitung. Durch Optimierungen speziell für Anwendungen in der Speicher- und Datenverwaltung kann die Technologie insbesondere in verteilten Speichersystemen eingesetzt werden und ermöglicht eine bis zu doppelt so hohe Geschwindigkeit wie traditionelle Erasure-Coding-Methoden, zum Beispiel Reed-Solomon-Codes. Die Technologie bildet zudem die Grundlage für die Erasure Coding Groups (EC-Groups) von Hammerspace.
Eines der Grundprinzipien der Mojette-Transformation ist es, eine Reihe von redundanten Datenblöcke (Projektionen) zu erzeugen, die einer Reihe von Codewörtern zugeordnet werden. Dazu werden die Daten zunächst in Teilmengen (Blöcke) aufgeteilt. Diese Blöcke sind in der Regel alle gleich groß und werden jeweils als 2D-Matrix dargestellt. Jedes Element in der Matrix entspricht einem einzelnen Bit im Block. Die Codewörter werden generiert, indem auf jede Matrix eine Reihe von linearen Transformationen angewendet wird. Die daraus resultierenden transformierten Matrizen (die sogenannten Codewörter) werden auf verschiedene Speicherorte (Knoten, Festplatten oder Rechenzentren) verteilt. Im Falle eines Datenverlusts können die ursprünglichen Daten aus einer Teilmenge rekonstruiert werden.
Auch Reed-Solomon-Codes basieren auf linearer Algebra. Anders als bei der Mojette-Transformation wird bei Reed-Solomon-Codes eine Folge von Datenpunkten (z. B. Bytes) durch ein mathematisches Polynom repräsentiert, aus dem Prüfwerte generiert werden. Die Ausfallsicherheit kann durch die Anzahl der Prüfwerte angepasst werden. Diese Kombination von Originaldaten und Prüfwerten erlaubt es, sowohl fehlerhafte Daten zu erkennen (z. B. beschädigte Bits) als auch, diese zu korrigieren. Reed-Solomon-Codes eignen sich besonders gut für Bereiche, in denen Datenintegrität entscheidend ist. RAID-6-Systeme verwenden Reed-Solomon-Codes, um Datenverluste bei Laufwerksausfällen zu verhindern. Die Herausforderung sind jedoch der hohe Rechenaufwand und eine höhere Latenz.
Hammerspace kombiniert die Leistung traditioneller Ansätze wie Reed-Solomon mit der Effizienz und dem reduziertem Rechenaufwand der Mojette-Transformation. Erasure-Coding ist mit der Mojette-Transformation hochgradig flexibel in Bezug auf die Anzahl der Knoten und die Menge der speicherbaren Daten. Im Vergleich zu traditionellen Methoden wie Reed-Solomon-Coding benötigt die Mojette-Transformation weniger Rechenleistung. Daten können schneller verteilt und rekonstruiert werden. Selbst eine Verteilung der Daten auf verschiedene Rechenzentren beeinträchtigt nicht die Wiederherstellungsfähigkeit. Die eingebaute Fehlertoleranz ermöglicht dem System, auch dann weiterzuarbeiten, wenn ein oder mehrere Server ausfallen. Der größte Vorteil besteht jedoch darin, die Originaldaten auch bei fehlenden Blöcken wiederherstellen zu können. Mit der Integration in das Global Data Environment von Hammerspace können Daten auf nahezu jeder handelsüblichen Hardware von den Vorteilen des Erasure Codings profitieren. Möglich wurde das unter anderem durch die Übernahme von Rozo Systems.
Hammerspace Tier 0 für leistungsstarke Anwendungsfälle
Die konsolidierte Datenplattform von Hammerspace verwendet ein auf Standards basiertes paralleles Filesystem mit einem globalen Namensraum. Hammerspace ermöglicht die Speicherung beliebiger Datentypen von beliebigen Anbietern einschließlich Cloudumgebungen über mehrere Standorte hinweg. Die integrierte Orchestrierungs-Engine automatisiert die Datenverwaltung mit Hilfe deklarativer Richtlinien, sogenannter Objectives. Die Hammerspace Hyperscale-NAS-Architektur eignet sich sowohl für Hyperscaler als auch für Unternehmen, da sie keine proprietäre Client-Software benötigt und effizient skaliert.
Der software-definierte und speicheragnostische Ansatz bringt auch älteren, bereits bestehenden NAS-Systemen einen Geschwindigkeitsschub. Das vereinfacht die Integration in eine bestehende Infrastruktur und schützt Investitionen. Hammerspace Tier 0 stellt GPUs Daten mit lokaler NVMe-Geschwindigkeit zur Verfügung und ist eine ideale Lösung für extrem leistungsstarke Anwendungsfälle wie KI und HPC-Checkpointing.
»Wir haben unermüdlich Innovationen entwickelt, um die Infrastrukturbarrieren zu beseitigen, die Datennutzer und Maschinen wie große Sprachmodelle, generative KI, Supercomputer und Datenanalysen behindern«, erklärt Flynn. »Die Zeiten, in denen proprietäre Software Daten an die Systeme band, in denen sie erstellt wurden, in denen riskante und mühsame manuelle Datenkopien erforderlich waren und in denen proprietäre, clientseitige Software IT-Probleme verursachte, sind vorbei. Die Zukunft der Daten ist nicht nur orchestriert, sie ist grenzenlos.« Der Gründer von Hammerspace trug maßgeblich zur Entwicklung der pNFS-Protokollspezifikation und dem daraus resultierenden IETF-Standard (RFC 5661) bei.
- Technical Brief zu Hammerspace Tier 0
- Hammerspace: Jeff Giannetti kommt als CRO von Weka