
Desaster beim Recovery: OVH fährt Cloud-Storage wieder hoch
Die Katastrophe am 10. März, deren Ursache nach wie vor ungeklärt ist, führte europaweit zum Ausfall der Cloud-Dienste des französischen Hosters OVHcloud. Rund drei Wochen später laufen die meisten Dienste wieder an, zumindest teilweise.
Seit dem Brand arbeitet das Unternehmen rund um die Uhr mit Spezialisten an der Bergung, Reinigung und Wiederherstellung von übrig gebliebener Hardware. Allein für die Reinigung eines Racks benötigen die Teams sieben Stunden, die unter Covid-19-Bedingungen unter erschwerten Bedingungen arbeiten. Hinzu kommen notwendige Sicherungsvorkehrungen beim Bewegen in den Bau-Ruinen.
 Der Gründer von OVH informiert am 10. März über den Vorfall und erhält 4.900 Likes (Quelle: twitter.com).Fragen nach der Datensicherheit und Notfall-Plänen konnte das Unternehmen bislang eher sporadisch beantworten. Seit dem Unfall, der nicht nur für den Anbieter, sondern auch Kunden eklatante Geschäftsschädigungen nach sich ziehen dürfte, ist man immerhin um Transparenz bemüht. Neben Echt-Zeit-Monitoring mit Listen geretteter Server und einem Online-Informationsforum für Kundenfragen veröffentlicht OVH regelmäßig Updates, teils über den Gründer und CEO Octave Klaba und seinen twitter-Account, zuletzt am Sonntag auch offiziell über seine Web-Seite. Die scheint zu funktionieren.
Der Gründer von OVH informiert am 10. März über den Vorfall und erhält 4.900 Likes (Quelle: twitter.com).Fragen nach der Datensicherheit und Notfall-Plänen konnte das Unternehmen bislang eher sporadisch beantworten. Seit dem Unfall, der nicht nur für den Anbieter, sondern auch Kunden eklatante Geschäftsschädigungen nach sich ziehen dürfte, ist man immerhin um Transparenz bemüht. Neben Echt-Zeit-Monitoring mit Listen geretteter Server und einem Online-Informationsforum für Kundenfragen veröffentlicht OVH regelmäßig Updates, teils über den Gründer und CEO Octave Klaba und seinen twitter-Account, zuletzt am Sonntag auch offiziell über seine Web-Seite. Die scheint zu funktionieren.
Rack für Rack: Neustart statt Recovery
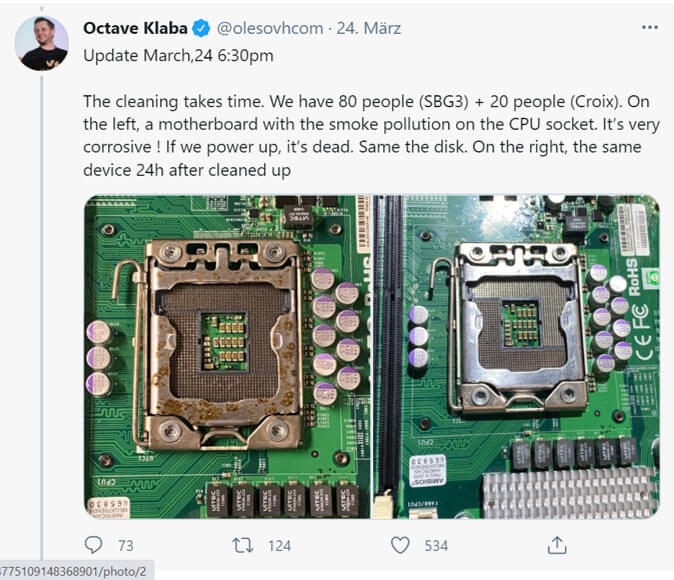 Die Bergung und Reinigung von Hardware ist Teil der ‚Recovery‘-Strategie von OVHcloud (Quelle: twitter.com). Laut Unternehmen, erfolgt die Wiederherstellung der Dienste nach einem Neustartplan Raum für Raum, Gang für Gang und Rack für Rack. Es sei jedoch eine Server-Bereinigung erforderlich, die bestimmt, wann bestimmte Racks wieder in Betrieb genommen werden.
Die Bergung und Reinigung von Hardware ist Teil der ‚Recovery‘-Strategie von OVHcloud (Quelle: twitter.com). Laut Unternehmen, erfolgt die Wiederherstellung der Dienste nach einem Neustartplan Raum für Raum, Gang für Gang und Rack für Rack. Es sei jedoch eine Server-Bereinigung erforderlich, die bestimmt, wann bestimmte Racks wieder in Betrieb genommen werden.
Nach den Angaben muss der Dienstleister noch 15.000 neue Server implementieren, um die vorherige Leistung zu erreichen. Alte und neue Hardware werden in den verbliebenen Gebäuden in Straßburg installiert, oder an andere Standorte verbracht. Stand 28. März ist das komplett zerstörte Rechenzentrum RGB2 abgeschalten – und bleibt es vermutlich auch. Übrig gebliebene Infrastruktur wird zu Rechenzentren in Gravelines (Niederlande), Roubaix (Frankreich), London (England), Warschau (Polen) und Frankfurt a.M. (Deutschland) verbracht.
SGB1 kann nach dem Brand derzeit noch nicht wieder in Betrieb gehen. Die noch verwendbaren Ressourcen werden nach der Reinigung am Standort in Straßburg in den Rechenzentren SGB3 und SGB4 untergebracht. Dort will OVH die Dienste im Laufe dieser Woche, voraussichtlich ab Dienstag, wieder aufnehmen. SGB3 sei zu 84 Prozent, SGB4 zu 100 Prozent in Betrieb.
Storage- und Backup-Dienste laufen wieder an
Das gilt für allgemeine Public-, Hosted- und Bare-Metal-Cloud-Dienste ebenso wie die Storage-spezifischen NAS-HA-Dienste des Anbieters. Veeam Cloud Connect und Veeam Managed Backup wurden nach Unternehmensangaben bereits am 25. März wieder gestartet. Host vSAN einen Tag später. Zumindest partiell. Viele Archive sind allerdings komplett verloren, andere nur teilweise wiederherstellbar. So sollen Public Storage Services (Objekt-Speicher) aus RGB3 ab dem 30. März wieder verfügbar sein, zunächst aber nur für Leseoperationen. Backup- und Snapshot-Dienste via PCI sollen ab 31. März wieder anlaufen.
Exakt an jenem Tag ist der weltweite World Backup Day, aber wohl kein Feiertag für OVH und seine Kunden. Die NAS-HA-Dienste, die mit »Priorität 2« kategorisiert werden, beschränken sich seit dem Update am 10. März auf 259 TByte. Mechanismen für einen Disaster-Recovery-Plan mit Kunden, sind sogar nur mit »Priorität 3« eingeordnet.