
Snowflake: Die Cloud ermöglicht neuartige Datenbank-Designs
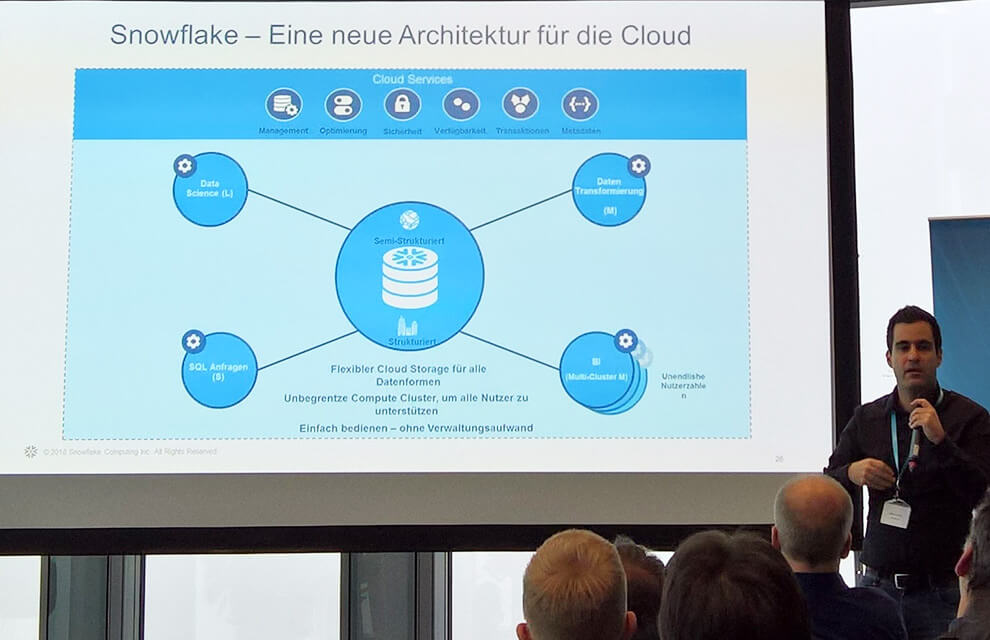 Dr. Artin Avanes erklärt den Aufbau der Snowflake-Lösung: In der Mitte der S3-Data-Lake, darum herum diverse virtuelle Warehouses und als übergreifende Schicht die von Snowflake erbrachten Cloud-Services (Bild: Arian Rüdiger).Die Datenbanknutzung in der Cloud ist noch relativ unausgereift. Zwar bieten alle großen Cloud-Anbieter irgendwelche Datenbanklösungen und analytische Umgebungen, häufig auf Hadoop-Basis, an. Auch die klassischen Hersteller von relationalen Datenbank-Produkten propagieren inzwischen Cloud-Instanzen ihrer Produkte oder machen es wenigstens möglich, dass Kunden die Datenbank auf eigene Faust in die Cloud migrieren.
Dr. Artin Avanes erklärt den Aufbau der Snowflake-Lösung: In der Mitte der S3-Data-Lake, darum herum diverse virtuelle Warehouses und als übergreifende Schicht die von Snowflake erbrachten Cloud-Services (Bild: Arian Rüdiger).Die Datenbanknutzung in der Cloud ist noch relativ unausgereift. Zwar bieten alle großen Cloud-Anbieter irgendwelche Datenbanklösungen und analytische Umgebungen, häufig auf Hadoop-Basis, an. Auch die klassischen Hersteller von relationalen Datenbank-Produkten propagieren inzwischen Cloud-Instanzen ihrer Produkte oder machen es wenigstens möglich, dass Kunden die Datenbank auf eigene Faust in die Cloud migrieren.
Eine Data-Warehouse-Lösung, die sich von Anfang an konsequent die Möglichkeiten der Cloud zunutze macht, suchte man bisher vergeblich. Mit Snowflake, dem derzeit ausschließlich auf AWS verfügbaren Service des gleichnamigen Silicon-Valley-Startups, ist nun eine solche Dienstleistung verfügbar.
Dass Snowflake ausgerechnet auf AWS startet, ist etwas pikant, denn mit Redshift hat der Provider selbst einen Dienst am Markt, dessen Funktionen man mit denen von Snowflake vergleichen könnte. Die Unterschiede liegen hier aber im Detail. Der wichtigste: Bei Snowflake werden Speicher und Rechenknoten konsequent in getrennten Schichten des Gesamtsystems gehalten und skalieren auch getrennt voneinander, bei Redshift nicht. Letzteres kann die Kosten gegebenenfalls negativ beeinflussen. Redshift ist eben aus einem von AWS erworbenen On-Prem-Produkt entstanden, also nicht Cloud-native.
Die Snowflake-Architektur
Die Architektur von Snowflake besteht aus drei Schichten: Die Daten werden auf S3 gehalten, wodurch der Datenspeicher nahezu unbegrenzt skalierbar ist. Die Rechenknoten befinden sich darüber und können ganz nach Kundenwunsch zu beliebig vielen Virtual-Warehouses in diversen sogenannten T-Shirt-Größen, also definierten Leistungsstufen, derzeit zwischen einem und 128 Rechenkernen, zusammengefasst werden. Da diese Ressourcen physisch unabhängig voneinander sind und ebenfalls per Knopfdruck bei Bedarf skalierbar sind, sollen sie beliebig viele parallele Zugriffe unter unterschiedlichen Aspekten auf denselben Datenbestand ermöglichen. Darüber befindet sich eine Service-Schicht, in der die Metadaten und -funktionen wie beispielsweise Sicherheit, Authentisierung und Nutzungsstatistik stattfinden. Auch diese Schicht skaliert unabhängig von den beiden anderen.
Abgerechnet wird bei Snowflake auf zwei Ebenen: Kunden zahlen für die verbrauchte Speichermenge, wobei die Kosten hier bei 23 Dollar pro TByte und Monat beginnen, und zwar für die komprimierten Daten. Die Kompressionsrate gibt Dr. Artin Avanes, Direktor Produktmanagement, mit fünf bis zehn an. »Damit sind wir billiger als AWS S3 im Original – wir wollen definitiv kein Geld damit verdienen, dass wir Daten speichern.«
Die zweite Kostenkomponente ist die Nutzung der Rechenknoten. Hier wird mit Credits kalkuliert, von denen einer der Nutzung eines Knotens für eine Stunde entspricht. Abgerechnet wird aber im Sekundentakt, nämlich nur dann, wenn ein virtuelles Warehouse tatsächlich aktiv ist und Daten analysiert. Das An- und Abschalten von Warehouses lässt sich sogar automatisieren, etwa, wenn jeden Monatsletzten ein analytischer Durchlauf anfällt, um festzustellen, welche Maschinen wo und wann einen Schaden hatten und wie dieser behoben wurde.
Weil das An- und Abschalten sowie das Skalieren von Warehouses so schnell geht, lassen sich mit Snowflake beliebig viele Warehouses für einen Kunden parallel betreiben, beispielsweise für unterschiedliche Abteilungen oder Spezialisten mit einer Analyse-Infrastruktur zu versorgen oder um im Rahmen von Tests unterschiedliche Lösungen für ein Problem parallel auszuprobieren.
Sicherheit: Redundant und Verschlüsselt
Sicherheit und Zuverlässigkeit erfüllen professionelle Ansprüche: Kunden können frei eine Retentionsdauer für die Daten festlegen und dann jederzeit auf einen früheren Zustand zurückfahren, zum Beispiel, weil ein Data-Warehouse mit einem Virus verseucht oder durch Fehleingaben funktionsgestört ist. Daten werden ab der Übergabe an Snowflake-Treiber von Ende zu Ende verschlüsselt. Das Schlüsselmanagement übernimmt Snowflake, wobei auch Lösungen möglich sind, bei denen ein Schlüsselteil beim Kunden liegt und erst das Zusammenfügen der beiden Schlüsselkomponenten von Provider und Kunde zu einem Gesamtschlüssel die Dechiffrierung der Daten ermöglicht. Das entspricht dem Vier-Augen-Prinzip in der physischen Welt.
Für eine mehrfache Redundanz ohne weiter Vorkehrungen ist bereits gesorgt: Snowflake betreibt seine Services derzeit schon in fünf AWS-Regionen, davon mit Frankfurt und Dublin zwei in Europa. Zudem werde alle drei Systemschichten nicht nur zwischen Regionen, sondern auch zwischen den in einer Region befindlichen Rechenzentren gespiegelt.
Kompatibel zu vielen Datenbanken und Tools
Der Service ermöglicht Abfragen in klassischem SQL, kommt aber über Konnektoren, die von dem Unternehmen entwickelt wurden, auch mit anderen Abfrageformaten zurecht, die dann in SQL umgesetzt werden. Das ist wichtig, weil sich derzeit durch das Web Formate wie JSON stark verbreiten, mit denen konventionelle relationale Datenbanken nicht zurechtkommen. Dasselbe gilt auch für andere Datenbankformate, hier hilft unter anderem der ETL-Spezialist Talend, zu dem Snowflake eine enge Partnerschaft unterhält.
Bei der Bereitstellung des Service über AWS soll es nicht bleiben. Avanes: »Wir verstehen uns definitiv als Multicloud und Multilocation.« Der Zeitpunkt, wann Snowflake bei anderen Providern verfügbar sein wird, ist derzeit noch offen. Azure-Kunden, die den Dienst ausprobieren wollen, können aber immerhin seit Kurzem ihre Daten zur Analyse mit Snowflake in dessen AWS-Instanz importieren.
Die Funktionsvielfalt wird stetig erweitert: Mit SnowPipe, das auf Serverless oder Lambda-Computing von AWS zurückgreift, sollen sich Daten schnell in den Service von Snowflake laden lassen. Angekündigt wurde Virtual Private Snwoflake, eine kundenspezifische Cloud-Instanz des Dienstes. Mit AWS Private Link können Daten demnächst auch über sichere nichtöffentliche Verbindungen zu Snowflake gesandt werden.
Snowflake kooperiert mit Talend und Qubole
Für ihre Expansion setzt die Software-Schmiede auf zahlreiche Partnerschaften, technische und vertriebliche: Neben Talend war auf der ersten deutschen Firmenpräsentation in München auch Tableau vertreten, Spezialist für am Arbeitsplatz durchführbare ad-hoc-Analysen mit anspruchsvoller grafischer Ergebnisdarstellung. Der jüngste Partner von Snowflake ist Qubole, ein Big-Data-as-a-Service-Anbieter. Man will Kunden ermöglichen, den Clustermanager Apache Spark in einem Qubole-Service zusammen mit virtuellen Data-Warehouses auf Basis des Snowflake-Service einzusetzen. Die Kooperation ist ein Beispiel dafür, wie sich heute durch die Cloud aus mehreren Services integrierte Komplettdienste entwickeln, die genau wie bisher komplexe Hardware-Produkte oft aus OEM-Produkten unterschiedlicher Anbieter zusammengesetzt waren.
Der indische IT-Dienstleister Wipro war ebenfalls vor Ort. Er rät seinen Kunden zu Snowflake, wenn sie mit der Geschwindigkeit bisheriger DW-Lösungen unzufrieden sind und in die Cloud migrieren wollen. In Deutschland sucht man nun Integrationspartner.
Mit seinem Angebot sieht sich Snowflake als Alternative zu den oft kostspieligen firmeninternen Data-Lakes, in denen in den vergangenen Jahren wohl so manches Unternehmen Millionen an Investitionsgeldern versenkt hat. Martha Bennett, leitende Analystin bei Forrester: »Wir gehen davon aus, dass 60 bis 80 Prozent von ihnen, so, wie sie dastehen, wieder abgeschaltet werden.« Das liege daran, dass sie am Bedarf vorbeigeplant wurden bzw. der Bedarf überhaupt nicht auf sinnvolle Weise analysiert wurde. Snowflake-Kunden bleiben davor zwar nicht automatisch bewahrt - sie benötigen aber auch beim Einstieg ins analytische Computing in der Cloud wenigstens nicht Unsummen in Hard- und Software zu investieren.