
IBM: Cognitive Storage agiert wie menschliches Gehirn
Wie kann man Computern beibringen, wie sie zwischen wichtigen und unwichtigen Daten unterscheiden können? Mit dieser Fähigkeit könnte ein Computer dann automatisch entscheiden, welche Daten auf welchem Level der Speicherhierarchie und für wie lange gespeichert werden sollen. Klingt etwas wie Storage-Tiering – aber ein neues, von IBM-Forschern entwickeltes Storage-Konzept namens Cognitive Storage, ist mehr.
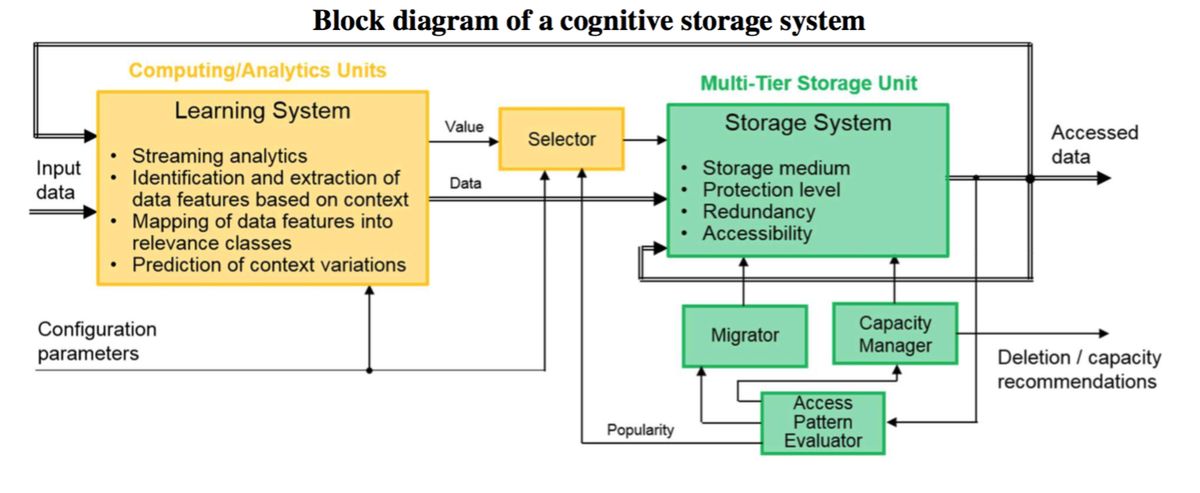 So läuft es im Prinzip in einem Cognitive-Storage-System ab (Bild: IBM)Besonders im Hinblick auf steigende Energiekosten und das exponentielle Datenwachstums in Zeiten von Big Data, unter anderem vorangetrieben durch das Internet der Dinge (Internet of Things, IoT), ist die effiziente Datenspeicherung eine kritische Herausforderung. Denn durch intelligente Speicherprozesse wären signifikante Einsparungen in der Speicherkapazität und damit ein geringerer Verbrauch an Speichermedien und Energie möglich.
So läuft es im Prinzip in einem Cognitive-Storage-System ab (Bild: IBM)Besonders im Hinblick auf steigende Energiekosten und das exponentielle Datenwachstums in Zeiten von Big Data, unter anderem vorangetrieben durch das Internet der Dinge (Internet of Things, IoT), ist die effiziente Datenspeicherung eine kritische Herausforderung. Denn durch intelligente Speicherprozesse wären signifikante Einsparungen in der Speicherkapazität und damit ein geringerer Verbrauch an Speichermedien und Energie möglich.
Cognitive-Storage-Konzept basiert auf der Maßeinheit »data value«
 Dr. Jens Jelitto, IBM Research Center Zürich (Bild: IBM Research)Cognitive Storage, ein neues, von IBM-Forschern entwickeltes Storage-Konzept, könnte hier ein Lösungsansatz sein. Doch wie funktioniert Cognitive Storage? Zunächst ein Seitenblick, wie das menschliche Gehirn arbeitet. Schließen Sie Ihre Augen und denken Sie an Ihren letzten Urlaub zurück. Die Erinnerungen, die Ihnen geblieben sind, sind jene Eindrücke, denen Ihr Gehirn automatisch eine große individuelle Bedeutung zugemessen hat – zum Beispiel ein schöner Sonnenuntergang oder ein besonderes Abendessen. Gleichzeitig werden nebensächliche Eindrücke – wie zum Beispiel das Warten an einer Ampel oder das Einchecken in den Flieger – vom Gehirn als unwichtig qualifiziert und somit schnell vergessen. Und Dr. Jens Jelitto vom IBM Research Center Zürich ist sich sicher: »Mittels kognitiver Datenspeicherung können Computer dasselbe leisten.«
Dr. Jens Jelitto, IBM Research Center Zürich (Bild: IBM Research)Cognitive Storage, ein neues, von IBM-Forschern entwickeltes Storage-Konzept, könnte hier ein Lösungsansatz sein. Doch wie funktioniert Cognitive Storage? Zunächst ein Seitenblick, wie das menschliche Gehirn arbeitet. Schließen Sie Ihre Augen und denken Sie an Ihren letzten Urlaub zurück. Die Erinnerungen, die Ihnen geblieben sind, sind jene Eindrücke, denen Ihr Gehirn automatisch eine große individuelle Bedeutung zugemessen hat – zum Beispiel ein schöner Sonnenuntergang oder ein besonderes Abendessen. Gleichzeitig werden nebensächliche Eindrücke – wie zum Beispiel das Warten an einer Ampel oder das Einchecken in den Flieger – vom Gehirn als unwichtig qualifiziert und somit schnell vergessen. Und Dr. Jens Jelitto vom IBM Research Center Zürich ist sich sicher: »Mittels kognitiver Datenspeicherung können Computer dasselbe leisten.«
In einem vor kurzem erschienenen Artikel im IEEE-Fachjournal »Computer« erörtern Dr. Jelitto und seine Forschungskollegen Giovanni Cherubini und Vinodh Venkatesan das Konzept der kognitiven Datenspeicherung, welches derzeit in Entwicklung ist und bald in Beta-Tests eingesetzt werden soll. »Unsere Idee basiert auf einer Maßeinheit, die wir ‚data value’ nennen«, erläutert Dr. Jelitto. »Dieser Wert, der einer Datei beigemessen wird, verhält sich ähnlich wie der Wert eines Kunstobjekts: Je höher die Nachfrage und/oder die Seltenheit eines Objekts ist, desto höher wird in der Regel ihr Wert sein, deshalb muss dieses sorgfältiger geschützt und aufbewahrt werden.«
Kognitives System erkennt Verwendungsprofil einer Datei
Wenn zum Beispiel in einem Unternehmen 1.000 Angestellte tagtäglich auf eine Datei zugreifen, sollte diese Datei – fast wie ein einzigartiger Van Gogh – einen sehr hohen Datenwert (engl. »data value«) haben. Ein kognitives System würde laut Dr. Jelitto dieses Verwendungsprofil erkennen und in der Folge die Datei für den zuverlässigen und schnellen Zugriff zum Beispiel auf Flash-Speicher speichern: »Außerdem würde es automatisch diverse Sicherungskopien anlegen und unter Umständen die Datei auch durch zusätzliche Sicherheitsmechanismen, wie zum Beispiel Benutzerautorisierung, schützen.«
Natürlich gibt es in einem Unternehmen auch Dateien, bei denen das Gegenteil der Fall ist. Eine Datei, auf die nur selten zugegriffen wird, beispielsweise ein 20 Jahre altes Steuerdokument, würde durch ein kognitives Storage-System auf preiswerte »cold media« – wie beispielsweise Tape – gespeichert werden, und wäre nur auf Anfrage zugänglich.
Cognitive-Storage-Test ergab fast hundertprozentige Vorhersagegenauigkeit des Datenwertes
Ein solches System würde außerdem wissen, dass Steuerdokumente nur für einen bestimmten Zeitraum gespeichert werden müssen, und würde nach Ablauf dieser Frist deren Datenwert herabstufen oder sie sogar löschen. »Im Laufe der Zeit ändert sich der ‚data value’ natürlich auch, ein kognitives Datenspeichersystem kann darauf entsprechend reagieren«, erklärt Dr. Jelitto. »Eine Möglichkeit, den Wert einer Datei zu bestimmen, ist die permanente Beobachtung der Zugriffsmuster und der -häufigkeit auf die Daten. Die Nutzer können – je nachdem, in welchem Kontext die Daten genutzt werden – diesen außerdem Metadaten oder Tags zufügen und damit das System trainieren.« So könnte zum Beispiel ein Astronom Daten, die aus der Andromeda-Galaxie stammen, als sehr wichtig oder weniger wichtig markieren.
Und Cognitive Storage lässt sich sogar schon praktisch testen. »Für den Beitrag in dem Fachjournal haben wir das Cognitive-Storage-Konzept mit 1,77 Millionen Dateien von sieben Benutzern getestet. Dazu nutzten wir ein einfaches, dreistufiges Klassensystem, wobei der Datenwert auf Basis der zugehörigen Metadaten (Benutzer ID, Gruppen ID, Dateigrösse, Zugriffsberechtigung, Erstelldatum und Zeit, Datentyp und Pfad) ermittelt wurde«, gibt Dr. Jelitto Einblick in den Test. »Danach wurden die Serverdaten nach Dateien pro Benutzern aufgeteilt, damit jeder Nutzer selbst die Wichtigkeit der Daten für sich individuell bewerten konnte. Das Ergebnis war eine fast hundertprozentige Vorhersagegenauigkeit des Datenwertes in diesem relativ kleinen Datensatz.«
IBM-Forscher führen in das Cognitive-Storage-Konzept ein