
Orientierungshilfe: Leistungsstarke Storage-Infrastruktur für KI
 Eine optimale Storage-Infrastruktur ist entscheidend für den Erfolg von KI-Anwendungen. Der Leitfaden beleuchtet die Unterschiede zwischen Trainings- und Inferenzphasen und deren spezifische Anforderungen an Speicherlösungen. Wir erklären, warum NVMe-SSDs, skalierbare Architekturen und schnelle Netzwerkverbindungen erfolgskritisch sind und zeigen Strategien zur Leistungssteigerung und Kosteneffizienz auf.
Eine optimale Storage-Infrastruktur ist entscheidend für den Erfolg von KI-Anwendungen. Der Leitfaden beleuchtet die Unterschiede zwischen Trainings- und Inferenzphasen und deren spezifische Anforderungen an Speicherlösungen. Wir erklären, warum NVMe-SSDs, skalierbare Architekturen und schnelle Netzwerkverbindungen erfolgskritisch sind und zeigen Strategien zur Leistungssteigerung und Kosteneffizienz auf.
Die Storage-Infrastruktur ist entscheidend für den Erfolg von KI-Anwendungen. Dabei müssen verschiedene Aspekte berücksichtigt werden: Große Kapazität, niedrige Latenz, hoher Durchsatz, Skalierbarkeit, Datenbeständigkeit oder die Integration mit den gängigen KI-Werkzeugen und Frameworks sind ebenso wichtig wie die wirtschaftliche Tragfähigkeit einer Lösung. Bei komplexen maschinellen Lernprozessen (Machine-Learning, ML) spielen zudem erweiterte Funktionen wie Metadaten-Management oder Versionierung eine wesentliche Rolle. Die Vielzahl dieser Anforderungen unterscheidet Storage für KI-Workloads von Speicherprodukten für klassische Unternehmens-Anwendungen wie ERP oder CRM. Auch bei den KI-Workloads selbst gibt es Unterschiede: Das Training beispielsweise eines großen Sprachmodells (Large Language Model, LLM) stellt andere Anforderungen als dessen praktische Anwendung. In diesem Artikel gehen wir auf Bedürfnisse an die Leistung ein, erklären warum diese wichtig sind, und stellen geeignete Storage-Architekturen bzw. Lösungen vor.
Prämisse: Unterschied zwischen Training und Inferenz berücksichtigen
Bei der Betrachtung der Speicheranforderungen für KI-Anwendungen (Künstliche Intelligenz) ist es wichtig, zwischen den beiden Hauptphasen Training und Inferenz zu unterscheiden. Jede der beiden Phasen stellt eigene Anforderungen an Speichersysteme. Das Verständnis dieser Unterschiede ist entscheidend für die Auswahl und Implementierung geeigneter Speicherlösungen, die sowohl die Trainings- als auch die Inferenz-Phasen von KI-Anwendungen effektiv unterstützen und so eine optimale Leistung und Effizienz im gesamten KI-Workflow gewährleisten. Das Training erfordert erhebliche Investitionen in skalierbare, leistungsstarke Speicherplattformen. Bei der Inferenz kommt es vor allem auf Geschwindigkeit und Zuverlässigkeit an.
Im Unternehmenskontext müssen geeignete Speicherlösungen beide Phasen optimal bedienen können. Selbst vortrainierte KI muss auf ihre spezielle Einsatzumgebung abgestimmt werden und kontinuierlich weiterlernen. Das ist notwendig, um sich an unternehmensspezifische und neue Daten, Muster oder Anforderungen anzupassen. Dieser Prozess wird als maschinelles Lernen oder Machine-Learning (ML) bezeichnet. Je mehr Daten ein KI-System verarbeitet, desto besser kann es Muster erkennen, Vorhersagen treffen und Entscheidungen treffen. Ohne kontinuierliches Lernen würden die Ergebnisse mit der Zeit weniger präzise oder die KI gänzlich obsolet werden. Die Leistungsfähigkeit wiederum wirkt sich im Betrieb unmittelbar auf das Nutzererlebnis aus und kann in bestimmten Einsatzszenarien sogar sicherheitskritisch werden.
Leistung und Kapazität
KI-Workloads erfordern eine konstant hohe Leistung. Für das Training greifen KI-Anwendungen häufig sequentiell auf Daten zu. Hohe IOPS (Input/Output Operations Per Second) und konstant schnelle Lese- und Schreibvorgänge gewährleisten eine reibungslose Leistung auch bei Spitzenbelastungen. Skalierbare Speicherlösungen ermöglichen es Unternehmen, wachsende Datenmengen ohne Leistungseinbußen zu bewältigen. Mit Load-Balancing lässt sich die Belastung auf verschiedene Speichergeräte verteilen. So kann die Gesamtleistung erhöht und Engpässe vermieden werden.
Bei der Inferenz kommt es vor allem auf die effiziente Ausführung der vorab trainierten Modelle an. Je nach Anwendung entscheiden Modellgröße (Anzahl der Parameter) und Kontextlänge (maximale Größe der kombinierten Eingabe und Ausgabe) über die Relevanz der Ergebnisse. Je mehr Informationen zur Verfügung stehen und in Kontext gesetzt werden können, desto genauer ist das Resultat. Ein Modell mit 70B Parametern liefert bessere Antworten als ein Modell mit 7B Parametern. Größere Modelle und Sequenzlängen haben jedoch andere Ansprüche an die Rechenleistung und Speicherbandbreite.
Skalierbare, verteilte Speicherlösungen (zum Beispiel Ceph, HDFS oder Lustre) ermöglichen die effiziente Verwaltung großer Datenmengen. RAID bzw. Erasure-Coding sorgt für eine hohe Verfügbarkeit der Daten. Eine Herausforderung kann die Verteilung der Daten über unterschiedliche Plattformen und Standorte hinweg sein. Eine effiziente Metadatenverwaltung ist entscheidend für die Organisation der Datenstruktur und beschleunigt die Suche nach bestimmten Datensätzen.
Als primäre Speicherlösung sollten ausschließlich NVMe-SSDs (Non-Volatile Memory Express Solid State Drives) eingesetzt werden. Weniger häufig genutzte Daten lassen sich auf kostengünstigeren Speichermedien abgelegen, wie Festplatten oder Bandlaufwerken (Tape). Die Integration von Cloud-Speicherlösungen ermöglicht eine kurzfristige Skalierung nach Bedarf. Das kann insbesondere für große und variable Workloads von Vorteil sein.
Scale-out vs. Scale-up
Vor allem für das Training künstlicher Intelligenz wird eine Vielzahl unterschiedlicher Informationen benötigt. Die Speicherlösungen müssen über eine große Kapazität verfügen und mit großen Datensätzen umgehen können. Je mehr Daten zur Verfügung stehen, desto genauer oder relevanter kann das Ergebnis ausfallen. Das gilt sowohl für das Training als auch für die Anwendung, beispielsweise in Analysen (Analytic AI) oder Vorhersagen (Predictive AI). Eine Plattform sollte also nahtlos skalierbar sein. Scale-out-Architekturen sind einfacher im Betrieb und daher besser geeignet als ein reiner Scale-up-Ansatz.
In einer Scale-out-Architektur kann die Kapazität im laufenden Betrieb beliebig erweitert werden. Beim Scale-up-Ansatz setzt die Hardware der maximal möglichen Erweiterungen eine physische Grenze. Das Clustern einzelner Appliances zu einem logischen Verbund ist komplexer und erfordert oft spezielles Fachwissen. Sowohl die Installation als auch der Betrieb können komplex und aufwändig sein. Selbstverständlich können auch einzelne Geräte in einer Scale-out-Architektur mit einzelnen Komponenten wie Arbeitsspeicher oder HDDs bzw. SSDs nachgerüstet werden. Vor allem Speicherkapazität lässt sich bei den gängigen Herstellern problemlos im laufenden Betrieb ergänzen. Gegebenenfalls müssen IT-Manager die RAID-Konfiguration manuell anpassen.
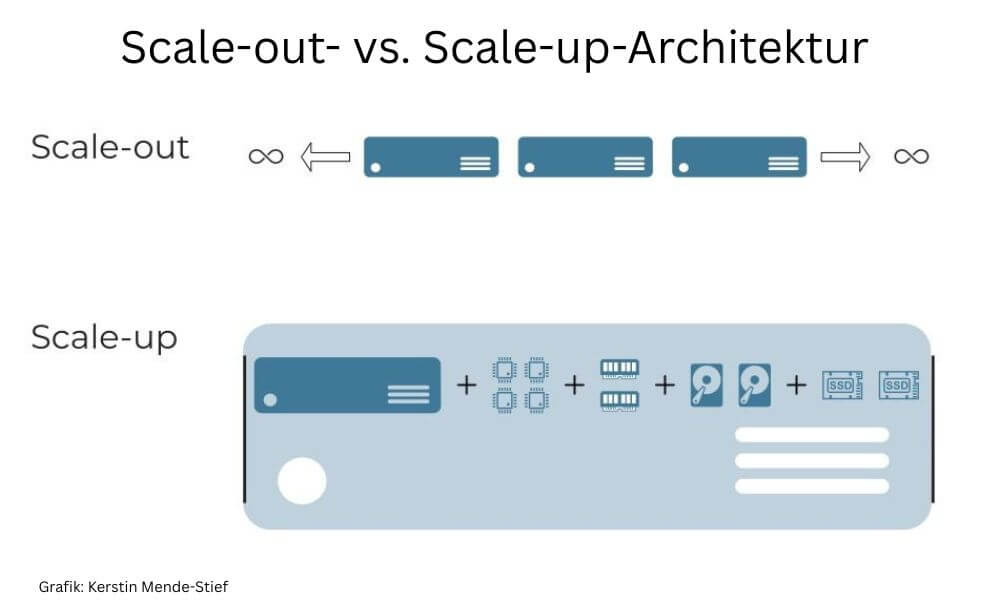 Bei einer Scale-out-Architektur wird die Kapazität durch Hinzufügen neuer Geräte erweitert. Beim Scale-up werden einem Gerät einzelne Komponenten wie Arbeitsspeicher, zusätzliche Prozessoren oder Festplattenkapazität hinzugefügt. (Grafik: Kerstin Mende-Stief) Übersicht:
Bei einer Scale-out-Architektur wird die Kapazität durch Hinzufügen neuer Geräte erweitert. Beim Scale-up werden einem Gerät einzelne Komponenten wie Arbeitsspeicher, zusätzliche Prozessoren oder Festplattenkapazität hinzugefügt. (Grafik: Kerstin Mende-Stief) Übersicht:
Netzwerk und Kommunikation
Kritisch sind bei KI-Workloads insbesondere Laufzeiten bei Dateizugriffen (Latenz) und die Geschwindigkeit, mit der Daten gelesen bzw. geschrieben werden können. Physische Limitationen wie Bandbreite oder Einschränkungen aufgrund veralteter Technologie können zu Ineffizienz führen. Jeder Weg, den die Daten zurücklegen, jede Schicht, die sie durchlaufen, jeder Kontextwechsel und jede Protokollübersetzung verursachen Verzögerungen. Netzwerk-Protokolle wie TCP belasten den gesamten Übertragungsweg und erhöhen die Paketumlaufzeiten besonders zwischen entfernten Standorten.
Kommunikation mit Speichermedien
Eine wichtige Rolle im Hardware-Stack spielen unter anderem die der Übertragung zugrunde liegenden Protokolle. Das speziell für SSDs entwickelte NVMe-Protokoll basiert auf dem PCIe-Standard und erlaubt es Speichermedien, direkt mit der CPU zu kommunizieren. Zusätzliche Controller oder die für SAS/SATA benötigten AHCI- bzw. SCSI-Adapter sind nicht nötig. Der Vorteil wird beim Vergleich der Latenzen deutlich, die sich von mehr als 100 Millisekunden (ms) bei SATA über 100 Mikrosekunden (µs) mit SAS auf bis zu 10 µs bei PCIe reduzieren lassen.
Features wie ein Full-Duplex-Mode sind bei gleichzeitigen Schreib- und Lesezugriffen nützlich. Zwar ist auch SAS full-duplex-fähig. Allerdings sind die Bandbreiten bei PCIe – und damit NVMe – um ein Vielfaches höher. PCI-Express-Verbindungen unterstützen bis zu 16 Lanes, die gebündelt werden können. Die aktuell genutzte PCIe Gen 5 ermöglicht eine Datenübertragungsrate von knapp 4 GByte/s pro Lane. Mit jeder neuen Generation verdoppelte sich bisher die Bandbreite. Die für 2025 angekündigte Gen 7 soll knapp 16 GByte/s pro Lane erlauben. SAS hängt seit über zehn Jahren bei 12 GByte/s fest, für den schnelleren 24G-Standard (SAS-4) gibt es kaum Geräte. Die Anbindung schneller Speichermedien wie SSDs sollte daher prinzipiell über NVMe erfolgen. Die Hardware muss dafür passende Anschlüsse für NVMe-Geräte bieten (M.2, U.2/U.3 oder EDSFF).
Auch bei den IOPS gibt es große Unterschiede. Hochleistungs-SSDs schaffen über 1 Million IOPS. Das hat unter anderem mit der unterstützten Anzahl Warteschlangen (Queues) und Befehlen je Warteschlange (Kommandos oder engl. Commands) zu tun. PCIe unterstützt 64.000 (64k) Command-Queues mit jeweils 64k Befehlen pro Queue. Zum Vergleich: eine SATA-Schnittstelle unterstützt gerade mal eine einzelne Queue mit maximal 32 Befehlen. Das dem SAS zugrunde liegende SCSI-Protokoll erlaubt nur 256 Kommandos in der (einzigen) Command-Queue.
An dieser Stelle wird deutlich, dass Storage nur einen Teil der Infrastruktur für KI-Anwendungen darstellt. Die schnellste NVMe-SSD ist nutzlos, wenn der Prozessor oder das Motherboard eines Servers die hohen Standards nicht unterstützen oder die einzelnen Knoten mit 100 Mbit/s Ethernet verbunden sind.
Netzwerk-Infrastruktur
Bei KI-Anwendungen beeinflusst die Entfernung der Daten zu den Rechen-Ressourcen sowohl die Latenz als auch die Leistung. Schnelle Netzwerkverbindungen wie Infiniband (unter anderem Nvidia) oder das inzwischen quelloffene Omni-Path (Cornelis Networks) beschleunigen die Übertragung von Daten zwischen Storage und Rechenknoten. Beide sind Implementationen von RDMA (Remote Direct Memory Access), das den direkten Zugriff auf entfernte Speicher ermöglicht, ohne CPUs und Hauptspeicher der jeweiligen Rechner zu belasten. Latenz wird quasi auf die Signallaufzeit der zugrunde liegenden physischen Leitung (Kupfer, Glas) reduziert (wire speed).
Sowohl Infiniband als auch Omni-Path sind Entwicklungen aus dem High Performance Computing (HPC) und benötigen spezielle Switches. Die Investitionskosten können höher sein als für herkömmliche Rechenzentrumsnetzwerke auf Ethernet-Basis. Der Betrieb erfordert fachspezifische Kenntnisse.
Für die Nutzung der im Enterprise-Umfeld verbreiteten Ethernet-Netzwerke empfehlen sich Protokolle wie RDMA-over-Converged-Ethernet (RoCE). RoCE basiert auf dem User Datagram Protocol (UDP). Im Gegensatz zu TCP gilt UDP als unzuverlässig. Mit RoCEv2 wurde unter anderem ein Kontrollmechanismus definiert, der Bestätigungsbenachrichtigungen erlaubt. Zudem setzt RoCEv2 auf UDP/IPv4 bzw. UDP/IPv6 auf, was die Pakete routingfähig macht. Für den Einsatz eines Ethernet-Switches in Converged-Ethernet (CE) Umgebungen sind spezielle Features erforderlich, die über die Funktionen eines Standard-Ethernet-Switches hinausgehen.
Mit iWARP ist RDMA auch über das Internet (IP) möglich. iWARP setzt auf dem Transmission-Control-Protocol (TCP) auf und ist damit ebenfalls routingfähig. Gegenüber UDP sind in TCP mehr Kontroll- und Sicherheitsmechanismen implementiert. Funktionen wie dreifacher Handshake für den Verbindungsaufbau oder Fehlererkennung und die erneute Übertragung unvollständiger oder verlorener Pakete erhöhen zwar die Zuverlässigkeit, wirken sich jedoch auf die Latenz aus. Der Protokoll-Overhead beansprucht zudem mehr Bandbreite, was besonders Verbindungen zu Edge-Standorten belastet.
Für verteilte KI-Workloads (zum Beispiel in Cluster-Umgebungen) sollten Daten und Rechenknoten idealerweise in der gleichen Netzwerkdomäne sein.
Datenmanagement
KI arbeitet sowohl mit strukturierten als auch mit unstrukturierten Daten wie Datenbanken, Bildern und Textdateien. Das Speichersystem muss diese verschiedenen Datentypen effizient verwalten und abrufen können.
Die Bereinigung der Daten führt zu relevanteren Ergebnissen und entlastet die Infrastruktur (Festplatten-I/O, Speicherplatzbedarf, CPU-/GPU-Last, Netzwerkverkehr). Beim so genannten Data-Pruning werden irrelevante Daten ausgeschlossen und redundante Informationen entfernt (Deduplizierung).
Komprimierung der Daten vor der Ablage kann die Übertragungsmenge reduzieren. Allerdings ist zu beachten, dass bereits komprimierte Formate wie JPEG, MP3, H.265 oder MPEG sich nicht wesentlich weiter komprimieren lassen. Aus dem HPC stammende Formate wie HDF5 oder zarr sind für den Umgang mit großen Datasets optimiert. Auch lassen sich Daten für die Übertragung serialisieren. Dafür werden die Daten in ein für den Transport geeignetes Format konvertiert.
Von besonderer Bedeutung für KI sind Metadaten. Es wird zwischen drei Haupttypen unterschieden: administrativ, strukturell und informativ. Die Informationen ermöglichen es, Daten zu strukturieren, zu organisieren, zu kategorisieren, zu klassifizieren und vor allem, sie auch wiederzufinden. Informative Metadaten liefern zudem einen wichtigen Kontext für das Training und den Betrieb von KI-Algorithmen. Metadaten müssen nicht nur aktuell, sondern vor allem vollständig sein. Moderne Storage-Plattformen sind in der Lage, Metadaten automatisiert zu erfassen und zu organisieren. Dennoch sollten menschliche Mitarbeiter sowohl Vollständigkeit als auch Richtigkeit zumindest stichprobenartig prüfen.
Richtlinien helfen bei der Ablage von Daten. Vor allem in verteilten Systemen ist es wichtig, bereits in der Planungsphase die Dateistruktur und Ablageorte für bestimmte Daten festzulegen.
Checkpointing
Beim Checkpointing wird der aktuelle Zustand eines Modells (Gewichte, Parameter, Optimierungsvariablen) regelmäßig gespeichert. Das ist besonders wichtig beim Training speziell mit Deep-Learning-Algorithmen, das sich oft über lange Zeiträume hinweg ziehen kann. Wird ein Training aufgrund eines Systemfehlers oder anderer Störungen unterbrochen, kann das Training von einem gespeicherten Zustand (Checkpoint) neu gestartet werden. Das hilft ebenfalls bei der Verarbeitung großer Datensätze. Mit Hilfe von Checkpoints kann das Training an einem bestimmten Punkt pausiert und später fortgesetzt werden. Mit Checkpointing lassen sich auch verschiedene Versionen eines Modells speichern. Dies kann nützlich sein, um die Entwicklung des Modells über die Zeit hinweg zu analysieren und mit früheren Versionen des Modells zu vergleichen.
Die Herausforderung beim Checkpointing ist es, wertvolle Ressourcen wie GPUs und Netzwerk nicht zusätzlich zu belasten. Je nach Sprachmodell und Anzahl der Parameter des Modells können Checkpoints zwischen einigen hundert GByte bis zu mehreren TByte groß werden. Checkpoints sollten also so nah wie möglich am Prozessor gespeichert werden. Lokaler NVMe-Speicher in GPU-Servern wird aufgrund seiner Isolation kaum genutzt. Durch die Integration dieser Hochleistungs-Ressource in den globalen Namensraum können KI-Modell-Checkpoints lokal geschrieben werden.
Die Server verfügen über mindestens zwei, in der Regel acht leistungsstarke lokale NVMe-Laufwerke. Hersteller wie Supermicro bieten Server an, die bis zu 16 lokale NVMe-Laufwerke unterstützen. Die Kapazität einer NVMe-SSD beträgt zwischen 4 und 8 TByte. SSDs der Enterprise-Klasse sind mit 30 TByte und 60 TByte erhältlich. Solidigm und KIOXIA haben bereits 122-TByte-Laufwerke für 2025 angekündigt. Der Strombedarf für die Speicherkapazität ließe sich mittelfristig im Vergleich zum Einsatz externer Netzwerke und Speicher um bis zu 95 Prozent reduzieren.
Anbieter wie Hammerspace haben das Potential dieses Tier 0, wie sie es nennen, erkannt und bereits in ihre Global Data Platform integriert. In einem Test wurden 500-GByte-Checkpoints in einer GPU-H100-Instanz in zirka 4,5 Sekunden auf lokale NVMe-Speicher geschrieben. Selbst mit teuren 400 Gbit/s Infiniband-Switches und dem schnellsten verfügbaren externen Speicher dauerte das Schreiben von Daten über das Netzwerk fast 2,5mal länger als das direkte Schreiben auf den lokalen NVMe-Speicher in einem GPU-Server. In einem cloudbasierten Szenario mit einer GPU H100-Instanz und Hochleistungs-EBS (io2) in AWS dauerte derselbe Auftrag mit 139 Sekunden über 31 mal länger. Mit dem lokalen NVMe-Speicher werden GPU-Ressourcen um ein Vielfaches schneller wieder für andere Aufgaben freigesetzt, was bis zu 20 Prozent mehr Leistung bringt und zu echten Kosteneinsparungen führt. Bei großen GPU-Clustern kann sich das auf Millionen Euro an zurückgewonnenem Wert summieren. Selbstverständlich können auch aktive Datensätze für die Zeit der Verarbeitung lokal auf GPU-Servern gehalten werden. Damit würden sich Effizienzsteigerung und Kostenersparnis auf sämtliche KI-Workloads auswirken.
Sicherheit und Datenintegrität
Datenintegrität ist für KI-Anwendungen von größter Bedeutung, insbesondere bei langen Trainingszeiten. Speicherlösungen sollten weitgehend immutable sein. Funktionen wie Erasure-Coding oder wenigstens Replikation gewährleisten die Verfügbarkeit der Daten und helfen, Datenverluste zu vermeiden. Regelmäßige Sicherungskopien von KI-Modellen und Daten sind unerlässlich, um bei Bedarf schnell wiederhergestellt werden zu können. Die Fähigkeit, verschiedene Versionen von Modellen zu verwalten, ist entscheidend, um ältere Versionen im Falle von Fehlern oder unerwarteten Verhaltensweisen eines neuen Modells schnell wiederherstellen zu können (Rollback). Ein gut durchdachter Notfall- und Wiederherstellungsplan gewährleistet, dass die Infrastruktur auch bei größeren Ausfällen schnell wieder betriebsbereit ist.
Die Verwendung von Verschlüsselungstechnologien sowohl für ruhende Daten als auch für Daten in Bewegung gewährleistet den Schutz sensibler Informationen. Mechanismen zur Zugriffskontrolle wie RBAC (Role-Based Access Control) sorgen dafür, dass nur autorisierte Benutzer Zugriff auf Anwendungen und Daten haben. Ein Rollen- und Berechtigungskonzept (RuB) hilft bei der Umsetzung. Komponenten, Anwendungen, Dienste und Schnittstellen müssen darin ebenso berücksichtigt werden wie menschliche Benutzer. Temporäre Ressourcen sind eine besondere Herausforderung. Deren Deaktivierung (auch Dekomissionierung oder Off-Boarding) wird oft vergessen nach der Benutzung. Automatisierung kann helfen, diese Angriffsfläche zu minimieren.
Die Storage-Architektur sollte so konzipiert sein, dass sie auch im Falle von Hardwareausfällen oder anderen Störungen weiterhin verfügbar bleibt. Monitoring-Werkzeuge sollten den Zustand der Speicherinfrastruktur in Echtzeit überwachen, um potenzielle Probleme frühzeitig zu erkennen und beheben zu können. Ein Monitoring mitsamt Baselining hilft frühzeitig zu erkennen, wann Speicherplatz oder Speicherperformance nachgekauft werden muss. Häufig helfen historische Zahlenreihen zu Auslastung und Wachstum auch dabei, das Management von notwendigen Anschaffungen zu überzeugen.
Die Architektur gewährleistet DSGVO- und HIPAA-Konformität durch umfassende Sicherheitsmaßnahmen wie Audit-Logging, das eine lückenlose Nachverfolgbarkeit aller Datenzugriffe ermöglicht.
Referenzarchitektur KI-Storage Enterprise
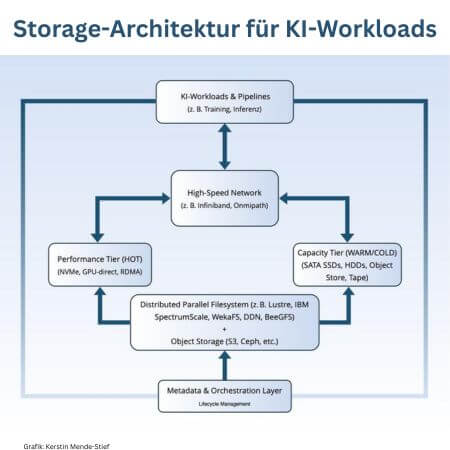 Im Zentrum der Architektur stehen das Highspeed-Netzwerk und eine funktionale Trennung zwischen einem Performance-Tier für hochfrequent genutzte Daten und einem Kapazitäts-Tier für skalierbare, kosteneffiziente Speicherung. (Grafik: Kerstin Mende-Stief)KI-Workloads – insbesondere im Training und bei der Inferenz großer Modelle – erzeugen massive Datenvolumina und erfordern hohe Bandbreite, geringe Latenz und flexible Skalierbarkeit. Eine moderne, auf diese Anforderungen zugeschnittene Storage-Architektur bildet das Rückgrat einer performanten und zukunftssicheren KI-Infrastruktur.
Im Zentrum der Architektur stehen das Highspeed-Netzwerk und eine funktionale Trennung zwischen einem Performance-Tier für hochfrequent genutzte Daten und einem Kapazitäts-Tier für skalierbare, kosteneffiziente Speicherung. (Grafik: Kerstin Mende-Stief)KI-Workloads – insbesondere im Training und bei der Inferenz großer Modelle – erzeugen massive Datenvolumina und erfordern hohe Bandbreite, geringe Latenz und flexible Skalierbarkeit. Eine moderne, auf diese Anforderungen zugeschnittene Storage-Architektur bildet das Rückgrat einer performanten und zukunftssicheren KI-Infrastruktur.
Das Performance-Tier ist auf maximale Leistung ausgelegt: NVMe-SSDs bieten in Kombination mit Technologien wie NVIDIA GPUDirect Storage (GDS) und Remote Direct Memory Access (RDMA) einen extrem schnellen Datenzugriff – ideal für Deep-Learning-Training auf GPU-Clustern. Typische Einsatzszenarien sind etwa Datenvorverarbeitung und das kontinuierliche Nachladen von Batch-Daten beim Modelltraining.
Beispielhafte Hardware-Plattformen in diesem Bereich sind DDN A³I Storage mit GDS-Support oder WEKApod von WEKA IO. Diese Systeme bieten hohe parallele Zugriffsraten und können direkt in Hochleistungsrechner integriert werden. Aktuelle Benchmarks sind von MLCommons verfügbar.
Das Kapazitäts-Tier dient der mittel- bis langfristigen Speicherung großer Datenmengen. Hier kommen in der Regel klassische HDDs, SATA-SSDs oder objektbasierte Speichersysteme zum Einsatz. S3-kompatible Object-Stores wie MinIO, Ceph oder Dell ECS ermöglichen dabei nicht nur die Speicherung unstrukturierter Daten in großem Maßstab, sondern unterstützen auch Funktionen wie Lifecycle-Management, Datenversionierung und automatisiertes Tiering. Kalte Daten lassen sich so automatisiert in Cloud-Archive oder Tape-Systeme überführen.
Zur Anbindung mehrerer Rechenknoten werden verteilte parallele Dateisysteme eingesetzt. Sie ermöglichen gleichzeitige Hochleistungszugriffe auf gemeinsame Datensätze und sorgen für eine gleichmäßige Auslastung der Infrastruktur. Etablierte Lösungen in diesem Bereich sind Hammerspace Hyperscale NAS, IBM Spectrum Scale (ehemals GPFS), Lustre, BeeGFS, WekaFS oder Ceph. Diese Filesysteme bieten ausgefeilte Mechanismen zur Datenplatzierung, Fehlertoleranz und Caching.
Zusätzlich zur Dateisystem- und Objektspeicherebene wird ein Metadaten- und Orchestrierungs-Layer integriert. Dieser umfasst etwa Kubernetes-Storage-Integrationen via CSI (Container Storage Interface), datengetriebene Workflow-Engines wie Apache Airflow oder Kubeflow sowie Tools zur Versionskontrolle von Daten und Modellen, etwa MLflow oder DVC (Data Version Control). Sie ermöglichen die dynamische Zuordnung von Speicherkapazität an Pipelines, automatische Datenbereitstellung für Trainingsjobs und reproduzierbare Workflows über Teams hinweg.
Anbieter von Data-Management-Lösungen erfassen Daten aus verschiedenen Quellen und helfen bei der Organisation, Verwaltung und Analyse. Hier sind einige Beispiele: Alationarbeitet mit Gamification als Motivator für die Pflege der Metadaten. Data Dynamicsist spezialisiert auf die Verwaltung unstrukturierter Daten und hat eine eigene KI entwickelt, mit der Daten unter anderem automatisiert klassifiziert werden können. Komprise legt großen Wert auf Informationssicherheit und schützt mit seinen umfangreichen Analysewerkzeugen sensible Informationen zuverlässig.
Der effiziente und unterbrechungsfreie Betrieb einer solchen Speicherarchitektur erfordert ein durchgängiges Monitoring- und Optimierungskonzept. Im Fokus stehen dabei Kenngrößen wie Bandbreite, Latenz, Zugriffsmuster, IOPS und die Auslastung einzelner Komponenten oder Tiers.
Mit Hilfe spezialisierter Tools wie Prometheus, Grafana, NetApp Active IQ oder DDN Insight können Unternehmen die Performance in Echtzeit überwachen, Engpässe frühzeitig identifizieren und auf Basis historischer Daten Kapazitätsplanungen durchführen. Darüber hinaus lassen sich Optimierungspotenziale – etwa beim Tiering-Verhalten oder in der Verteilung von Hot- und Cold-Data – gezielt aufdecken und automatisiert umsetzen.
Ein transparenter Einblick in die Storage-Nutzung ist nicht nur für technische Effizienz wichtig, sondern auch zur Kostenkontrolle und Einhaltung regulatorischer Vorgaben.
Fazit: Die perfekte Architektur besteht aus einer Kombination
Die perfekte Storage-Architektur für das Training von KI ist eine Kombination aus leistungsfähigen, skalierbaren und zuverlässigen Speicherlösungen, die hohe Geschwindigkeit, Redundanz und Sicherheit bieten. Durch die Integration von modernen Technologien wie NVMe-SSDs, verteilten Dateisystemen und Hochgeschwindigkeitsnetzwerken können die Anforderungen des KI-Trainings effektiv gemeistert werden. Darüber hinaus ist die Implementierung von Metadaten-Management, Sicherheitsfunktionen und Überwachungs-Tools entscheidend, um die Gesamteffizienz und Zuverlässigkeit der Storage-Architektur zu gewährleisten.